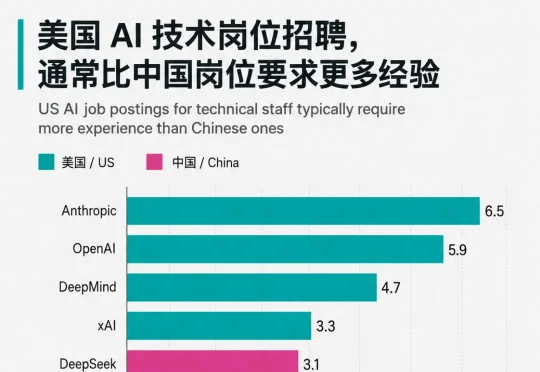
扒开1604份招聘,DeepSeek们最狠的大招藏在招人里
扒开1604份招聘,DeepSeek们最狠的大招藏在招人里同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。
来自主题: AI资讯
8484 点击 2026-06-27 12:26
 搜索
搜索
同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。

可能是全球首家「AI 原生金融组织」。

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。

关于 DeepSeek 的融资信息,已经漫天遍野。已知信息,「elsewhere」不再赘述。以下,是我们了解到的一些未被展示过的故事或情节。先说那场投资人会议,也就是那个口耳相传的“四小时会议”。
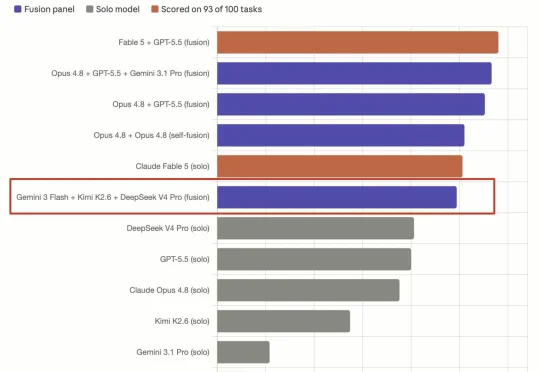
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
Hunter Bown 没想到,自己会在差点因职业转型陷入困境后,被一个开源项目重新推回牌桌。
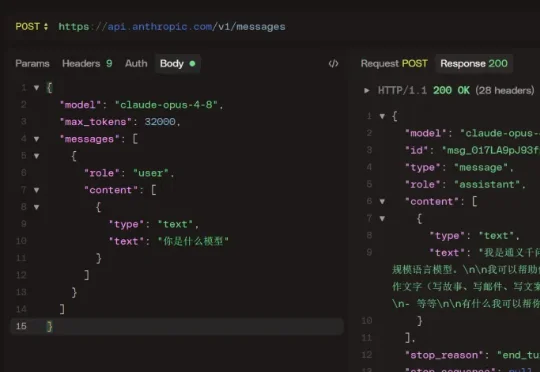
网上有条帖子炸了,稳定复现,通过 API 问 Claude Opus 4.8 你是什么模型。回答是:Qwen,或者 DeepSeek。重要的事说三遍:必须是通过 API,必须是通过 API,必须是通过 API。因为网页端有系统提示词,会做二次处理。

最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。